
嗨害大家好鸭!何用我是键保小熊猫❤

因为平台原因名字不能打出来…
但是大家应该都知道我是在说什么对吧?

我朋友天天打夜夜打…
这不,整个全的存绝绝美皮肤采集下来打包给他~

开发环境以及模块的使用:
- python 3.6
- pycharm
- requests >>>pip install requests
- os 内置模块 不需要安装的
整体流程:
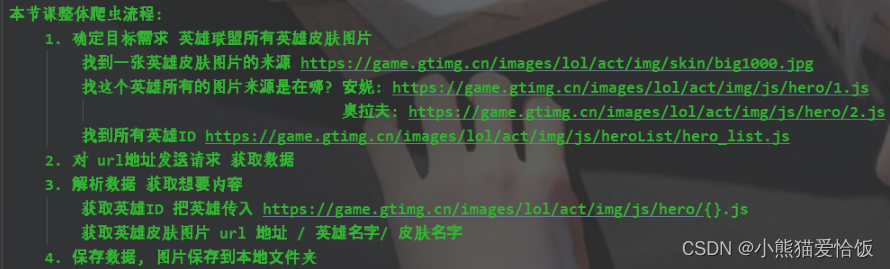
代码
import requests # 第三方模块 pip install requestsimport pprint # 格式化输出的模块 在打印json的数据的时候,可以更加方便 查看数据信息import os # 内置模块 不需要安装 自带的import re # 内置模块 不需要安装
def change_title(title): mode = re.compile(r'[\\\/\:\*\?\"\<\>\|]') new_title = re.sub(mode, '_', title) return new_titledef save(title, name, img_url): # 我想要把每个皮肤图片,单独保存在一个文件里面 filename = f'img\\{ title}\\' # 自动创建文件夹 # 如果没有这个文件夹 / 没有这个路径 那么就创建这个文件夹 if not os.path.exists(filename): os.mkdir(filename) # 获取图片内容,是要获取它一个二进制数据内容 # 文本数据 response.text json数据 response.json() 二进制数据 response.content img_content = requests.get(url=img_url, headers=headers).content with open(filename + name + '.jpg', mode='wb') as f: f.write(img_content) print(name)response = requests.get(url=url, headers=headers)# pprint.pprint(response.json())# 解析数据 获取 英雄ID# json数据提取数据 和 字典类似 根据关键字提取值 通俗的讲 根据冒号左边的内容 提取冒号右边的内容hero_list = response.json()['hero'] # 返回的数据内容 是列表形式# 通过遍历/for 循环 提取它每一个英雄IDlis = []for index in hero_list: hero_id = index['heroId'] lis.append(hero_id) # 字符串 格式化方法 # 对皮肤数据 url地址 发送请求 获取英雄皮肤图片数据lis = lis[27:]
# pprint.pprint(response_1.json()) # 解析数据 获取英雄皮肤url地址/英雄名字/皮肤名字 skins = response_1.json()['skins'] for index_1 in skins: # 皮肤图片地址 img_url = index_1['mainImg'] # 英雄名字 title = index_1['heroTitle'] # 皮肤名字 name = index_1['name'] new_name = change_title(name) new_title = change_title(title) if img_url: save(new_title, new_name, img_url) else: chroma_img = index_1['chromaImg'] save(new_title, new_name, chroma_img)效果
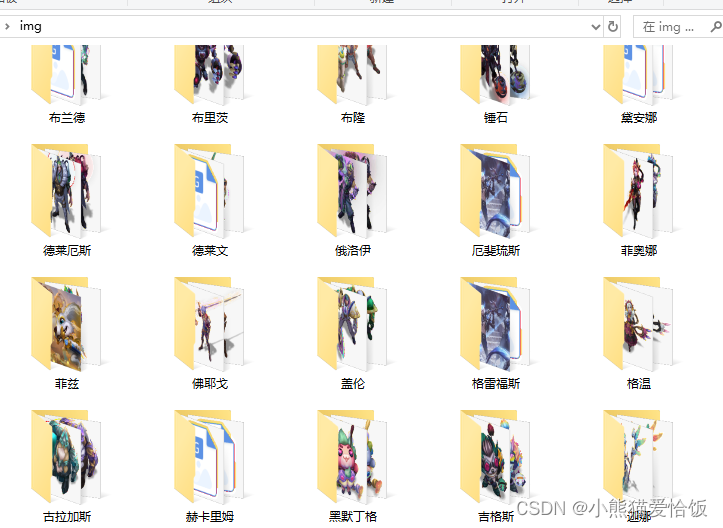




本文章到这里就结束啦~
感兴趣的小伙伴可以点击文末名片去试试哦 😝
我是小熊猫,美壁咱下篇文章再见啦(✿◡‿◡)















